
Context
Atlassian Crowd is an identity management server for Web Applications. It integrates very well with other Atlassian tools like JIRA, Confluence, Stash, Fisheye, Crucible, etc. We also used it with some custom plugins as Authentication and Authorization mechanism for our CI Servers (TeamCity), SonarQubue (via OpenID) and Source Code Repositories (SVN, Atlassian Stash).
Crowd was connected to Active Directory with LDAP connector and delegating Authentication to it. The picture bellow represents out setup.
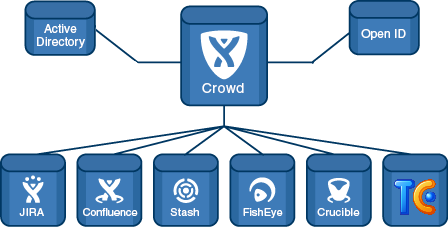
We had about 15000 users and 1500 groups across 3 directories. Each directory delegating authentication to Active Directory.
Performance issues
After a short while we started to get user complaining that they were unable to log in to JIRA or checkout code from Subversion, etc. Turned out that Crowd was slowing down. Profiling the system Crowd was running on showed us that there was plenty of CPU and Memory left for it.
The problem turned out to be Active Directory. Most specifically the slow response time for authentication requests into Active Directory at times of substantial load.
Plan and decision
We’ve decided that it would be nice to have a number of Crowd instances, serving different Applications.
Implementation
We’ve created Master -> Slave setup. All the users and groups’ management would happen in Master Crowd and propagate to Slave Crowd. We picked applications and grouped them by authentication load and set them up on appropriate Crowd Servers.
Crowd configuration got duplicated and catalogs imported so the Slave Crowd was still using Active Directory for authentication. Then we tackled the problem of keeping Crowd Master and Slave in Sync (users and groups).
Keeping Slave up to date
Unable to find a good out of the box solution we developed a Custom Crowd plugin and a bunch of web services.
Plugin functionality was rather simple: listen to any User or Groups events in Crowd (add/update/remove) and perform a simple HTTP get request with change details to preconfigured URL.
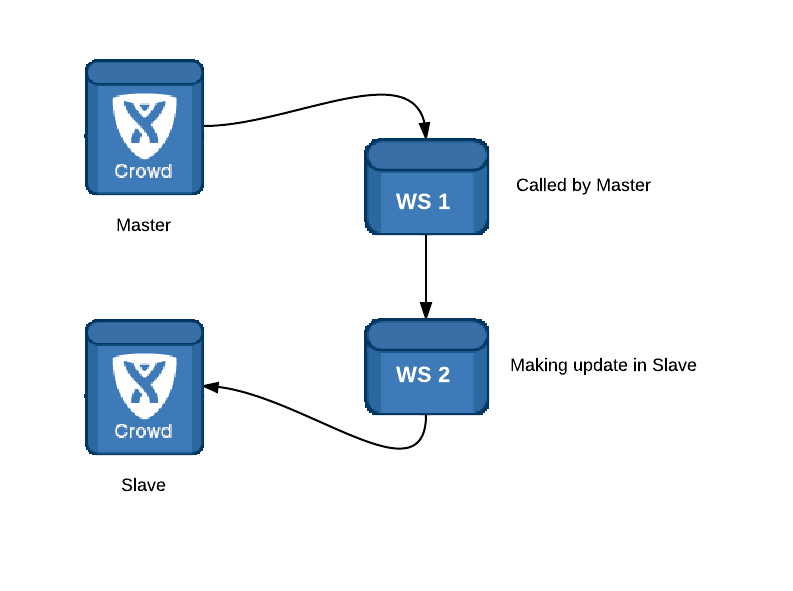
We’ve created two types of web services:
- The Web Services for the Crowd Plugin to call when the change happened. It was asynchronously calling to next Web Service that performed the changes in Slave Crowd.
- The Web Service performing changes in Slave Crowd.
The picture below represents the solution.
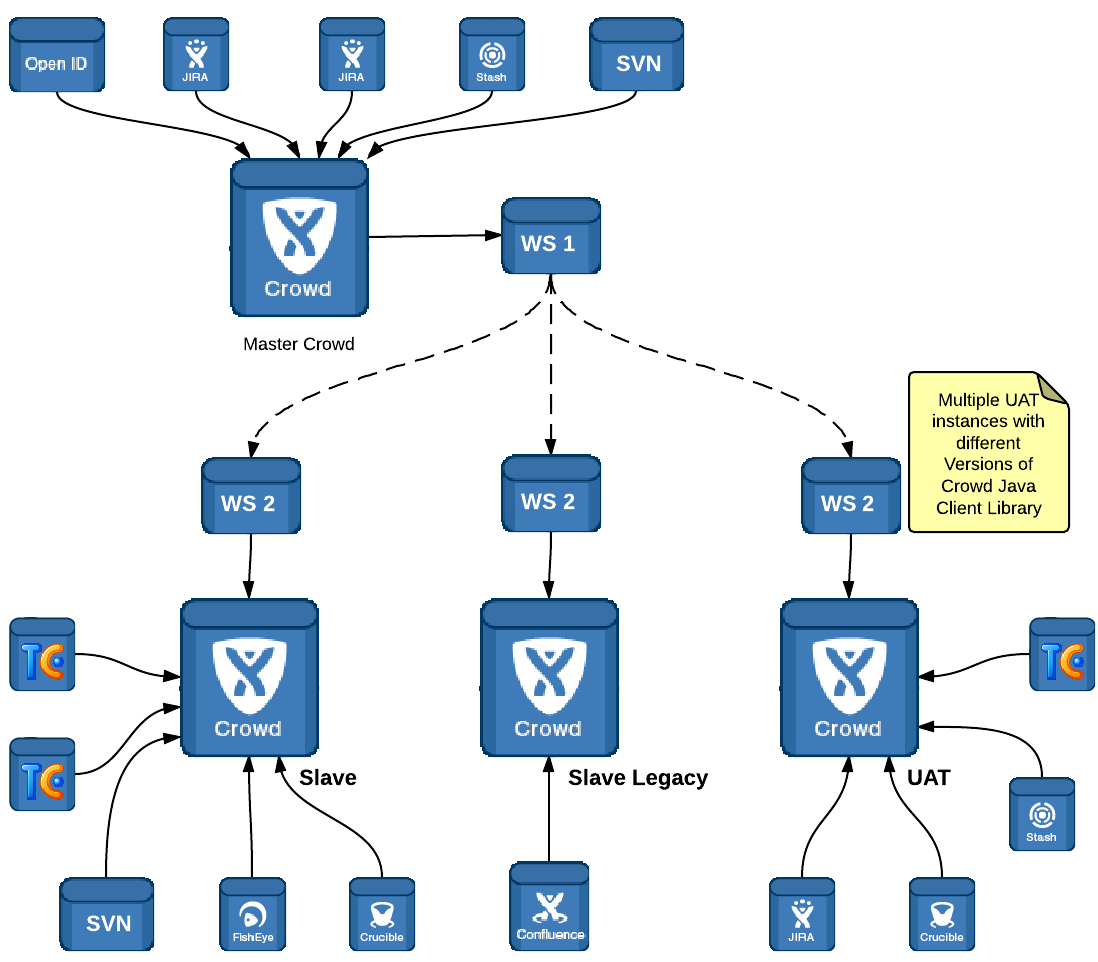
Multiple Slaves
We’ve ended up having multiple Crowd Slave instances. One of the instances had to be older and different version. Separating the Web Services gave us possibility for using different versions of Crowd Java Client Libraries.
We have also used this setup to keep our UAT environment with up to date data from Master Crowd.
The Web Services are stateless and have no database.
Full Crowd synchronization
As additional functionality we implemented full synchronization triggered from WS 1. WS 1 takes list of all the users and groups for each Directory from Master Crowd. Once collected it will call each WS 2 with full update.
This functionality makes it very easy to bring new UAT/DEV Crowd environments and populate it with Production data. It also makes it possible to Sync entire directory if one of the Web Services goes down.
Summary
The solution described above gave us horizontal scalability and possibility of working with different Crowd Client libraries and Crowd Versions. It also makes it easy to upgrade Crowd Instances.
